Indoor Sound Classification
Thesis Project 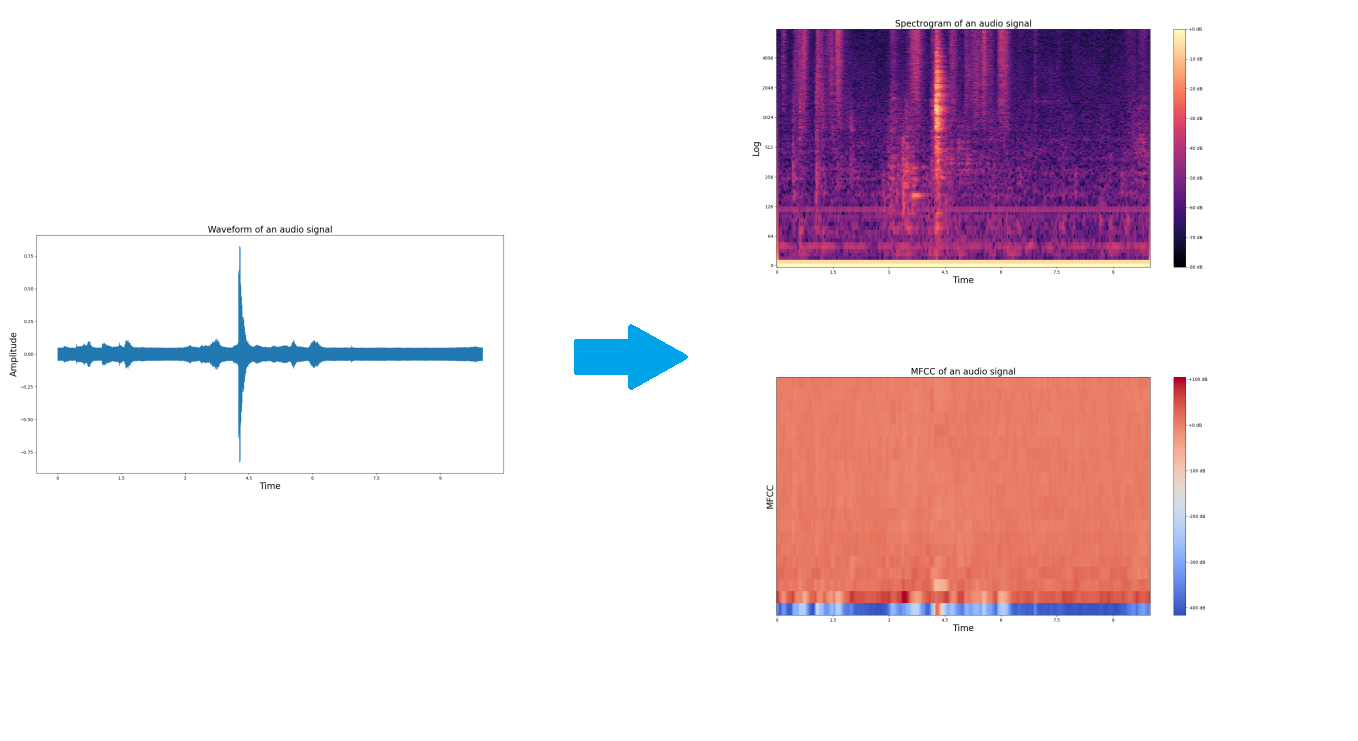

Thesis Project
Course Project for 05Θ25 - Digital Image Processing 
Published in Journal 1, 2009
This paper is about the number 1. The number 2 is left for future work.
Recommended citation: Your Name, You. (2009). "Paper Title Number 1." Journal 1. 1(1).
Download Paper | Download Slides | Download Bibtex
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2).
Download Paper | Download Slides
Published in UK & Ireland Speech Workshop 2025 Book of Abstracts, 2025
Phonemes are the basic speech unit with numerous studies exploring the inner workings of end-to-end transformer-based speech models, but they have mainly focused on Audio Speech Recognition (ASR). These studies have shown that there is significant phoneme capturing and encoding within the encoderlayers. The methodologies found in the literature include probing and the use of similarity measures, among others. Considerably less investigation into the interpretability of Audio-Visual Speech Recognition (AVSR) models has been done. In particular, no work has explored what AVSR models learn about visemes, the visual equivalent of phonemes. Our work therefore utilizes the concepts developed for ASR and applies them to AV-HuBERT, where a thorough analysis is performed to establish what the model learns about visemes.
Recommended citation: Papadopoulos, Aristeidis. (2025). "What does an Audio-Visual Speech Recognition Model know about Visemes?"
Download Paper
Published in Automatic Speech Recognition & Understanding (ASRU) 2025 Proceedings, 2025
Audio-Visual Speech Recognition (AVSR) models have surpassed their audio-only counterparts in terms of performance. However, the interpretability of AVSR systems, particularly the role of the visual modality, remains under-explored. In this paper, we apply several interpretability techniques to examine how visemes are encoded in AV-HuBERT a state-of-the-art AVSR model. First, we use t-distributed Stochastic Neighbour Embedding (t-SNE) to visualize learned features, revealing natural clustering driven by visual cues, which is further refined by the presence of audio. Then, we employ probing to show how audio contributes to refining feature representations, particularly for visemes that are visually ambiguous or under-represented. Our findings shed light on the interplay between modalities in AVSR and could point to new strategies for leveraging visual information to improve AVSR performance.
Recommended citation: Papadopoulos A. and Harte N. (2025) Interpreting the Role of Visemes in Audio-Visual Speech Recognition
Download Paper
Published:
This is a description of your talk, which is a markdown file that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate / Postgraduate course, Trinity College, Department of Electrical and Electronic Engineering, 2024
Teaching Assintant for 4C5-Digital Signal Processing. Duties include lab sessions in MATLab and grading of assignments. Course description can be found in link.
Undergraduate course, Trinity College, Department of Electrical and Electronic Engineering, 2025
Teaching assistant for 1e6 - Electrical Engineering. Duties include tutorials, lab sessions with circuits and grading of assignments. Course description can be found in link
Undergraduate course, Trinity College, Department of Electrical and Electronic Engineering, 2025
Teaching assistant for 2e12 - Computational Science & Engineering. Duties include lab sessions in MATLab and grading of assignments. Course description can be found in link